Xây dựng hệ thống xử lý background bằng ruby
1. Lợi ích của việc sử dụng background job
Đối với ứng dụng viết bằng Rails, mỗi khi có request đến, webserver tiếp nhận request và trả về resoponse, tại sao chúng ta cần sử dụng background? Bởi vì đối với những request cần phải tốn nhiều thời gian để xử lý như gửi email, import hay export với lượng data lớn, khi request được xử lý sẽ chặn các request khác, trong trường hợp xử lý quá lâu sẽ gây lỗi Timeout ảnh hưởng đến trải nghiệm người dùng. Để ứng dụng có thể hoạt động trơn chu, mượt mà hơn và ít bị người dùng chửi là web lởm vl 😬, người ta nghĩ ra cách cho những tác vụ này chạy trong nền. Ví dụ như việc xử dụng chức năng export CSV, khi người dùng click vào nút export thì ta sẽ cho phần export và generate file chạy ngầm, khi chạy xong thì gửi file cho người dùng,thao tác của người dùng không bị gián đoạn.
Bản thân Rails có Active Job, có chức năng là lưu trử và thực hiện các job, nhưng để enqueuing và executing job ta cần sử dụng framework thứ 3:
For enqueuing and executing jobs in production you need to set up a queuing backend, that is to say you need to decide for a 3rd-party queuing library that Rails should use. Rails itself only provides an in-process queuing system, which only keeps the jobs in RAM. If the process crashes or the machine is reset, then all outstanding jobs are lost with the default async backend. This may be fine for smaller apps or non-critical jobs, but most production apps will need to pick a persistent backend.
Rails có framework để thực hiện Background Job phổ biến như Sidekiq, Delay::Job, Sucker Punch, và những framework đó không nằm trong nội dung của bài viết này. 😁
2. Xây dựng hệ thống xử lý background bằng ruby
Extractitle Task
Giả sử ta có một list các website và phầ này ta xây dụng một task lần lượt lấy từng title từ url đó, bằng việc sử dụng OpenURI và Nokogiri:
require 'open-uri'
require 'nokogiri'
class TitleExtractService
def call(url)
document = Nokogiri::HTML(open(url))
title = document.css('html > head > title').first.content
puts title
rescue
puts "Unable to open #{url}"
end
end
TitleExtractService.new.call("http://xem.vn")
# Cộng đồng chế ảnh troll, xem ảnh vui nhộn, anh che haivl
Refactor một chút bằng việc thêm module Worker vào trong Object Service như sau:
module Extractor
module Worker
def self.included(base)
base.extend(ClassMethods)
end
module ClassMethods
def perform_now(*args)
new.perform(*args)
end
end
def perform
raise NotImplementedError
end
end
end
class TitleExtractWorker
include Extractor::Worker
def perform(url)
document = Nokogiri::HTML(open(url))
title = document.css('html > head > title').first.content
puts title
rescue
puts "Unable to open #{url}"
end
end
TitleExtractService.perform_now("http://xem.vn")
# Cộng đồng chế ảnh troll, xem ảnh vui nhộn, anh che hai
Giải thích một chút: ở đây ta tạo thêm module Worker, khi được include vào trong class, nhờ việc sử dụng method included, method trong module ClassMethods được extend cho TitleExtractWorker, khi đó ta có thể sử dụng method perform_now, nó sẽ tạo một instance và call method peform (trong có vẻ giống sidekiq 😉)
Implementing Asynchronous Process
Giả sử ta có một constant Title vơi list URL của các site cần phải lấy, mà list này từ đâu ra? Đối với người lười như mình thì dump lại cái URl nhiều lần có vẻ khả thi nhất ☺️
SITE_URLS = Array.new(10) { "http://xem.vn" }
SITE_URLS.each_with_index do |url, index|
puts "Numerical Order: #{index}, #{TitleExtractWorker.perform_now(url)}"
end
# Numerical Order: 0,
# Cộng đồng chế ảnh troll, xem ảnh vui nhộn, anh che haivl
# Numerical Order: 1,
# Cộng đồng chế ảnh troll, xem ảnh vui nhộn, anh che haivl
# Numerical Order: 2,
# Cộng đồng chế ảnh troll, xem ảnh vui nhộn, anh che haivl
# Numerical Order: 3,
# ....
Thanks God, it works 😂, nhưng điều kể đến ở đây là các việc các request được xử lý cách tuần tự, nghĩa là request sau phải chờ request trước hoàn thành rồi mới được thực thi.
Để tăng tốc độ sử lý ta thêm method perform_async bằng cách tạo thêm Thread để xử lý cho mỗi URL.
module Extractor
module Worker
module ClassMethods
def perform_async(*args)
Thread.new do
new.perform(*args)
end
end
end
end
end
Sau khi thay đổi bằng việc gọi TitleExtractWorker.perform_now(url), ta thu được tất cả các Title tại một thời điểm, tuy nhiên để làm được điều đó ta gần như mở 10 connection request tại một thời điểm 😂. Với thay đổi như thế này ta có thể gặp vấn đề về giới hạn cả server của ta (việc mở nhiều Thread đồng thời yêu cầu khả năng xử lý và tốn memory) và Site mà ta đang access (có thể xử lý đồng thời nhiều một lúc như thế hay không)
Queueing Task
Để xử lý vẫn đề trên ta sử dụng Producer–Consumer pattern, bằng cách xử dụng một Queue trung gian, mỗi khi có task phía Producer sẽ đấy task vào Queue và Consumer sẽ kéo task từ
Queue về và xử lý.
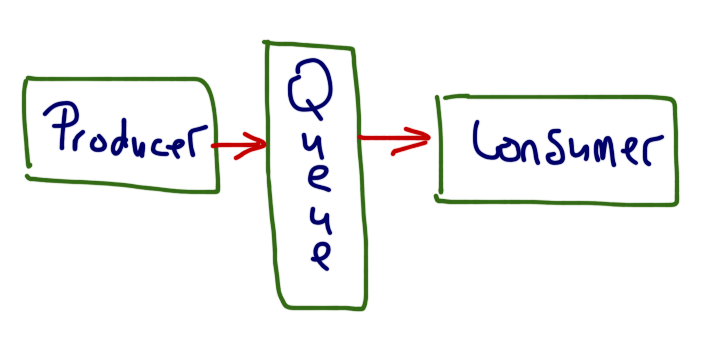
Ta thêm Queue như sau:
module Extractor
module Worker
def self.queue
@queue
end
def self.queue=(queue)
end
end
end
Extractor::Worker.queue = Queue.new
Và thay đổi method perform_async:
...
def perform_async(*args)
Extractor::Worker.queue.push(worker: self, args: args)
end
...
Đến phần tạo Consummer:
module Extractor
class WorkerExcuting
def self.start(concurrency = 1)
concurrency.times do |n|
new("Worker #{n}")
end
end
def initialize(name)
thread = Thread.new do
loop do
payload = Extractor::Worker.queue.pop
worker_class = payload[:worker]
worker_class.new.perform(*payload[:args])
end
end
thread.name = name
end
end
end
Ở phầ n này tùy thuộc vào số lượng Thread muốn thực hiện cách đồng thời mà ở khởi tạo ở phần start. Ta sử lại một chút method perform như sau:
def perform(url)
document = Nokogiri::HTML(open(url))
title = document.css('html > head > title').first.content
puts "Current worker #{Thread.current.name} excute #{title}"
rescue
puts "Unable to open #{url}"
end
Extractor::WorkerExcuting.start(4)
# Current worker Worker 0 excute Cộng đồng chế ảnh troll, xem ảnh vui nhộn, anh che haivl
# Current worker Worker 1 excute Cộng đồng chế ảnh troll, xem ảnh vui nhộn, anh che haivl
# Current worker Worker 2 excute Cộng đồng chế ảnh troll, xem ảnh vui nhộn, anh che haivl
# Current worker Worker 1 excute Cộng đồng chế ảnh troll, xem ảnh vui nhộn, anh che haivl
# Current worker Worker 3 excute Cộng đồng chế ảnh troll, xem ảnh vui nhộn, anh che haivl
# Current worker Worker 2 excute Cộng đồng chế ảnh troll, xem ảnh vui nhộn, anh che haivl
Queueing Task With Redis
Thay vì sử dụng Queue implement bở ruby phần này ta sử dụng Redis.
require 'redis'
require 'json'
module Extractor
module Worker
class Redis
def initialize(redis = ::Redis.new)
@redis = redis
end
def push(job)
@redis.rpush("extract_worker", JSON.dump(job))
end
def pop
_queue, payload = @redis.blpop("extract_worker")
payload = JSON.parse(payload, symbolize_names: true)
payload[:worker] = Object.const_get(payload[:worker])
payload
end
end
end
end
Extractor::Worker.queue = Extractor::Worker::Redis.new
Redis không phân biết được Ruby Object nên ta parse thành dạng JSON trước khi lưu trữ lại bằng Redis bằng việc sử dụng method rpush. Ta lấy object từ Redis bằng việc sử dụng
method blpop, khi Redis rỗng nó sẽ đợi cho tới khi có object có thể lấy được từ Redis, bằng cách này Worker cũng sẽ chờ cho tới khi Queue có data để xử lý. Việc cuối cùng là chuyển
String thành Object Class của Ruby khi đã fetch data từ Redis về. Để kiểm tra và chắc là Worker của mình hoạt động tốt, có thể mở terminal mới, add thêm job vào Redis queue và
xem điều kì lạ xảy ra =))
Leave a comment